Benchmarks: Dask Distributed vs. Ray for Dask Workloads
Dask Workloads
In this section, I detail the dask workloads that will be used to benchmark two cluster backends - Ray and Dask Distributed.
In summary, my dask workload involves processing ~3.3 Petabytes of ~6.06 million input files with dask-based Processing Chain and producing ~14.88 Terabytes of ~1.86 million output files.
Input Data
- ~6.06 million ~550MB files, totaling ~3.3 Petabytes
- Each file represents a N-dimensional numerical tensor (np.ndarray).
Processing Chain: How we go from Input data to Output data (Dask Task Graphs)
- We use Xarray /DaskAPIs for lazy, numerical computations on out-of-core multidimensional tensors.
- Per 3 input files, we generate 1 output file using below Dask Task Graph (auto generated by using Dask APIs)

- The Task Graph is consisted of small, Dask-level 'tasks'; tasks can be grouped into 3 actions:
- Load
- Download file from S3 and load each file into 2D np.ndarray of type np.float32
- Convert np.ndarray into dask.array of chunksize 0.25GB. Concatenate the dask.array into one dask.array.
- Compute some metadata & wrap the dask.array + metadata in an xaray.Dataset
- Transform:
- For each dask.array in the xarray.Dataset - apply multiple memory-heavy functions using dask.array.map_blocks or dask.array.map_overlapAPIs. Using these map APIs allow us to apply a function on a chunk-by-chunk basis so that workers can handle the computations in-memory. At the end, we end up with 3D xaray.Datasetwith dask.array
- Save:
- Using xarray.Dataset.to_zarr API, we save the resulting Xarrays in zarr format.
Output Data
- We end up with ~1.86 million 8MB zarr (xarray) files, totaling ~14.88 Terabytes
- This means that we'll be computing 1.86 million of the above graphs.
Dask Distributed vs Ray
Ray vs Dask Distributed - Comparison Summary
| Dimension | Dask Distributed | Ray | Winner |
|---|---|---|---|
| Efficient Data Communication Between Nodes | Source: https://distributed.dask.org/en/latest/serialization.html Data sharing happens via TCP messages between workers. Every time data should be shared, the task is serialized. Serialization schemes include msgpack, pickle+custom serializers, and pickle+cloudpickle. | Source: https://ray-project.github.io/2017/08/08/plasma-in-memory-object-store.html No serialization / TCP messages. Instead, shared data layer to enable zero-copy data exchange between nodes (Apache Arrow) object store. | Source: https://arrow.apache.org/blog/2017/10/15/fast-python-serialization-with-ray-and-arrow/ Ray Above article shows that Apache Arrow has huge speedup with numerical data (e.g. Numpy arrows) and moderate speedup with regular Python objects, over object serialization schemes (pickle) |
| Worker memory utilization | Source: http://distributed.dask.org/en/latest/memory.html In Dask Distributed, each worker must be specified with memory limit. A user would define this limit by studying the peak memory consumption of a given Dask Task Graph. If tasks in the task graph are unbalanced in terms of memory consumption, then this could lead to overprovisioning of the cluster just to accomodate for large memory consumption required by a subset of tasks. | Source: https://ray-project.github.io/2017/08/08/plasma-in-memory-object-store.html Since Ray has a Plasma object store that's shared by all workers, there's no need for each worker to be specified with memory limit. | Ray It's less time consuming for users to not have to specify memory limits of workers, since they do not have to figure out peak memory consumption of tasks. They can just spin up a sizable cluster, knowing that cluster RAM will be consumed as required. Also, because there's shared object memory store, I suspect that memory utilization will be higher in Ray. |
| Scheduler Fault Tolerance | Source: https://distributed.dask.org/en/latest/resilience.html Dask Distributed has one central scheduler. Above article says, "The process containing the scheduler might die. There is currently no persistence mechanism to record and recover the scheduler state." | Source: https://github.com/ray-project/ray/issues/642 Ray has bottom-up scheduling scheme where workers submit work to local schedulers, and local schedulers assign tasks to workers. The local scheduler also forward tasks to global schedulers. This means no single point of failure. | Source: https://github.com/ray-project/ray/issues/642 Ray In Dask, central scheduler can mean single central point of failure. Whereas in Ray, schedulers exist per machine, so less work is lost if a scheduler dies. |
Dask Distributed Cluster on EMR - Details
Dask is natively supported with "Dask Distributed" which is a separate library (than Dask) for distributed computing.
Dask Distributed can be set up on multiple cloud providers - we choose Dask-Yarn on EMR.
Cluster Architecture
Dask Distributed is centrally managed; meaning, there's the central dask scheduler process (on one machine), coordinating actions of several dask-worker processes (spread across multiple machines). The scheduler can handle concurrent requests of several clients (source). The scheduler tracks all work as Dask Task Graphs (as the one we have) as client submits them to the scheduler queue. Tasks in the Dask Task Graph are serialized and communicated over TCP between scheduler-worker, and worker-worker.

Source: https://distributed.readthedocs.io/en/1.10.2/scheduler.html
Ray Cluster on EC2 - Details
Ray is a different library from Dask and Dask Distributed. Similarly to Dask, it provides APIs for building distributed applications in Python. Unlike Dask, it does not provide big data collection APIs that we use such as dask.array, dask.delayed, etc.
Ray recently added support for Dask which "provides a scheduler for Dask (dask_on_ray) which allows building data analyses using Dask’s collections and execute the underlying tasks on a Ray cluster". This is the setup we are testing; Ray scheduler for handling Dask task graphs.
Ray can also be set up on multiple cloud providers - We use Ray Autoscaling Cluster on EC2.
Cluster Architecture
Unlike Dask, Ray has distributed scheduler scheme in every Head and Worker nodes. Tasks, instead of being serialized/communicated via TCP, are stored in the plasma object store and do not require TCP communications.
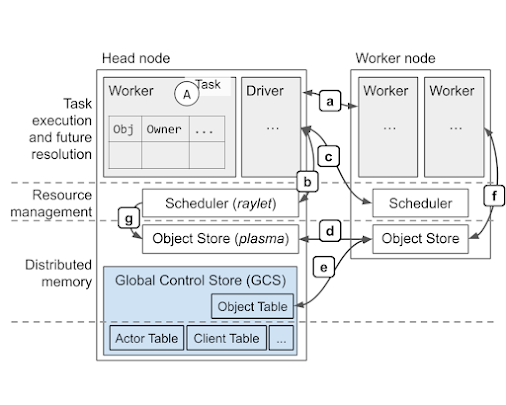
Source: Ray Whitepaper: https://docs.google.com/document/d/1lAy0Owi-vPz2jEqBSaHNQcy2IBSDEHyXNOQZlGuj93c/preview#
Benchmark Results Summary
| Dask Distributed | Ray | Winner | |
| Scalability Limit | Cluster memory: 20 TB RAM # EC2 Instances: 35 (200 of 100GB workers on 34 r5.24xlarge machines; 3,264 vCPUs)
| Cluster memory: 90 TB RAM # EC2 Instances: 249 (249 of r5n.12xlarge machines; 11,984 vCPUs) | Ray is tested upto scale x4.5 in terms of cluster RAM than Dask Distributed. Ray is tested upto scale x7.1 in terms of # EC2 instances than Dask Distributed. Note: If we used r5.24xlarge machines for Ray and it succeeded, then Ray would've been scaled x9 in terms of cluster RAM than Dask Distributed. |
Cluser Efficienty (Worker RAM / vCPU) | 5.9GB RAM / vCPU | 7.5GB RAM / vCPU | Ray is 27% more efficient than Dask Distributed in terms of how much RAM goes towards execution. |
| Throughput (# Dask task graphs processed / hour) | 0.1167 graph processed every hour per 1vCPU
| 0.4475 graph processed every hour per 1 vCPU | Ray has 4x higher throughput than Dask Distributed. |
| Cost of processing 1.86M Dask task graphs | $1,004,400
| $297,600 | Using Ray means we spend 29.6% of what we would've spent when using Dask Distributed. Not just % wise - using Dask Distributed becomes prohibitively expensive for our use case. |
| Time for processing 1.86M Dask task graphs | 195 days | 14.4 days | Due to combined effect of better scalability and throughput, using Ray is x13.5 faster than using Dask Distritubed. Note: If we used r5n.24xlarge instances instead of r5n.12xlarge instances, it's possible time is cut in half (due to 2x vCPUs). Work is in progress for scaling up to 500 nodes and this would cut down time by another half. |
Benchmark Results Details - Scalability
Dask Distributed Cluster on EMR
With Dask Distributed, we are limited by the number of Dask-worker processes we can use.
This is due to connection instability issues in Dask Distributed [1] [2].
Since the peak memory consumption in our Dask task graph is ~80GB (determined via using Dask profilers) we specify 100GB as memory limit of Dask workers. We saw failures happening at >250 workers, so we use 200 workers to be safe.
This means our Cluster RAM is limited at 100GB * 200 = 20TB
[1]: https://github.com/dask/distributed/issues/4080
[2]: https://github.com/dask/distributed/pull/4176
Ray Cluster on EC2
With Ray, we did not observe any connection stability issues when scaling up number of workers. A ray "worker" is essentially a vCore on an EC2 instance. Therefore, the number of worker processes we can use is "# vCore * # EC2 instances", and we are more limited by how many EC2 instances we can afford to provision at a given time.
If we had unlimited money and if EC2 doesn't run out of capacity in our AWS region (us-west-2), we could spin up thousands of EC2 instances. Then, theoretical limit in Ray becomes the hard limit of open file descriptors on a given EC2 instance (once heartbeat issus [1] [2] are addressed). This is because file descriptor limits represents the upper bound for the client connections, database files, log files, etc. In Ray, each Ray worker opens many connections to other nodes and Redis (data plane of the cluster) can have high concurrent connections, so theoretically a machine could run out of available file descriptors.
We saw some Redis-connection establishment failures at 500 nodes (potentially addressed by raising ulimits; pending verification). When using 250 nodes, we could successfully spin up the following cluster:
- Head instance: 1 r5.8xlarge
- Core instance: 249 r5.24xlarge (~750GB ram available for processes)
This means that Cluster RAM is tested up to ~360GB * 249 = ~90TB
[1]: https://github.com/ray-project/ray/issues/14337
[2]: https://github.com/ray-project/ray/pull/14336
Benchmark Results Details - Cluster Efficiency
Dask Distributed Cluster on EMR
We provision 200 of 100GB Dask-workers with the following EC2 instances:
- Client instance (EC2, outside of EMR) : 1 r5.8xlarge, submitting work to scheduler queue.
- Master instance (EC2, inside EMR) : 1 r5.24xlarge, running dask-scheduler process.
- Core instances (EC2, inside EMR) : 34 r5.24xlarge, running multiple dask-worker processes.
Total vCPU for this cluster is 32 (1 Client instance) + 96 (1 Master instance) + 96 * 34 (34 Core Instances) = 3392 vCPUs.
This means that 3392 vCPUs supported a 20TB cluster; cluster efficiency (in terms of how many worker RAM (GB) is supported per 1 vCPU) is 20TB RAM/3392vCPU = 5.9GB RAM / vCPU
Ray Cluster on EC2
Ray does not require a separate instance for "client" because the work can be directly driven inside Head instance.
- Head instance (EC2): 1 r5.8xlarge
- Core instance (EC2): 249 r5.12xlarge (~360GB ram available for processes)
Total vCPU for this cluster is 32 (1 Head instance) + 48 (249 Core instance) = 11,984 vCPUs.
This means that 11,984 vCPUs supported a 90TB cluster; cluster efficiency (in terms of how many worker RAM (GB) is supported per 1 vCPU) is 7.5GB RAM / vCPU
Benchmark Results Details - Throughput
Dask Distributed Cluster on EMR
- 13,865 Dask task graphs were processed between 02-08 20:37 and 2021-02-10 07:33 [1] on the 3,392 vCPU cluster
- Rate: ~396 (13865 / 35 hrs) graphs per 1 hour.
- How many graphs can be processed in 1 hour, given 1 vCPU?
- 396 graphs / 3,392 vCPU = 0.1167 graph every hour per 1vCPU
[1] https://us-west-2.console.aws.amazon.com/sagemaker/home?region=us-west-2#/processing-jobs/processing-processing-1612844758
Ray Cluster on EC2
- We compute batches of 1,000 Dask task graphs on the cluster. Observation is that it takes between 10-12 minutes for the 11,984 vCPU cluster to process the batch.
- We take an average of 5 randomly selected batches below to determine that it takes 11min & 11 seconds = 671 seconds to process 1000 graphs.
- Batch 1 (10 mins 49 seconds)
- START: 2021-02-21 20:48:45
- END: 2021-02-21 20:59:34
- Batch 2 (10 mins 24 seconds)
- START: 2021-02-21 23:49:42
- END: 2021-02-22 00:00:06
- Batch 3 (11 mins 56 seconds)
- START: 2021-02-23 16:00:25
- END: 2021-02-23 16:12:21
- Batch 4 (11 mins 10 seconds)
- START: 2021-02-24 09:22:32
- END 2021-02-24 09:33:42
- Batch 5 (11 mins 36 seconds)
- START: 2021-02-24 21:27:18
- END: 2021-02-24 21:38:54
- Batch 1 (10 mins 49 seconds)
- How many graphs can we process in 1 hour ?
- 1000 graphs / 671 seconds = 1.49 graphs / 1 second * 3600 seconds / 1 hour = 5365 graphs per hour.
- How many graphs can be processed in 1 hour, given 1 vCPU?
- 5365 graphs / 11,984 vCPU = 0.4475 graph every hour per 1 vCPU
Benchmark Results Details - Cost
Dask Distributed Cluster on EMR
- Cost per hour of running a 3,392 vCPU cluster
- $6.048 per hour (r5.24xlarge) * 35 + $2.016 per hour (r5.8xlarge) * 1 = $213.7
- Cost for processing 1 graph
- $213.696/hr for 396 graphs/hr = $0.54 per graph
- Cost for processing1.86M graphs
- $0.54 per graph * 1.86M = $1,004,400
Ray Cluster on EC2
- Cost per hour of running a 11,984 vCPU cluster
- $3.576 per hour (r5n.12xlarge) * 249 + $2.016 per hour (r5.8xlarge) * 1 = $892.4
- Cost for processing 1 graph
- $892.44/hr for 5365 graphs/hr = $0.16 per graph
- Cost for processing1.86M graphs
- $0.16 per graph * 1.86M = $297,600
Benchmark Results Details - Time
Dask Distributed Cluster on EMR
- Recall that rate for production was 396 graphs per 1 hour.
- How long does it take to process 1.86M graphs?
- 1,860,000/396 = 4696 hours = 195 days
Ray Cluster on EC2
- Recall that rate for production was 5365 graphs per 1 hour.
- How long does it take to process 1.86M graphs?
- 1,860,000/5365 = 346 hours = 14.4 days

This post is extremely insightful. Thanks for sharing it!
ReplyDelete